확률 분포들을 공부하다보면 항상 등장하지만 눈으로만 훑고 넘어가는 개념이 바로 '적률생성함수(mgf, Moment Generating Function)'입니다. 확률질량함수(pmf, Probability Mass function) 또는 확률밀도함수(pdf, Probability Density Function)를 공부하고 평균과 분산의 식을 본 다음 등장하곤 하죠. \(M_X(t)=E(e^{tX})\)라는 식과 함께 '그렇구나~'하고 넘어가서 제대로 그 뜻을 짚고 넘어가지 않는 경우가 많습니다. 사전지식을 많이 요하기도 하고 식이 너무 복잡하게 생겼기 때문일 겁니다. 하지만 통계학에서 상당히 중요하게 쓰이는 개념입니다. 어떤 확률변수의분포를 알고 싶을 때, mgf를 구해봄으로써 분포를 정확하게 알 수 있기 때문입니다.
1. 적률(모멘트, moment)의 정의
먼저 물리학에서는 모멘트(=돌림힘(Torque)=회전력)를 어떤 점(또는 축)을 중심으로 회전하려고 하는 힘으로 정의합니다. '어떤 물리량(대표적으로 질량)과 그 물리량이 있는 곳까지 수직거리의 곱'으로 계산하는데, 값이 커질수록 뭔가가 회전하도록 하는데 필요한 힘이 더 많이 필요하다고 이해하면 되겠습니다. 엄청 큰 츄파춥스 막대사탕을 들고 있다고 상상해볼까요? 사탕의 알이 볼링공만한데(=질량이 일정), 막대가 짧을 때보다 막대가 길 때(=수직거리 증가) 내가 사탕 알을 들고 회전하기 위해 필요한 힘이 훨씬 많이 들 것입니다.
이때 이 개념으로 '무게중심'을 구할 수 있습니다. 아래와 같은 지렛대가 있다고 생각해봅시다. 원점을 기준으로 각 물체의 위치가 \(x_i\)이고 질량이 \(m_i\)입니다. 지렛대의 받침점을 어떻게 구할 수 있을까요? 바로 무게중심을 구하는 식으로 구할 수 있습니다.
mgf는 \(x\)가 아니라 \(t\)에 대한 함수입니다! 이때 \(t\)는 위의 모멘트에서도 필요한 (거리 계산을 위한) 어떤 위치를 뜻합니다.
이름 그대로 '적률을 만들어내는' 함수이기 때문에 이렇게 이름이 붙은 것이라고 하네요. 어떻게 적률을 생성해내는 것일까요? mgf를 급수 전개한 후, 미분해서 얻어낼 수 있답니다. 미분하면 신기하게도 모든 차수의 적률을 얻을 수 있습니다. 각 차수 적률의 의미는 조금 뒤에 살펴보도록 하겠습니다.
사실은 우리가 원점에 대한 \(k\)차 적률 \(\mu'_k\)를 지금까지 따져보았고, 일반적인 적률의 모양새는 이렇습니다.
$$\mu'_k=E((X-c)^k))$$
\(c=0\)일 때, '원점'에 대한 \(k\)차 적률이라고 불렀던 것이죠.
이때 \(c\)자리에 평균 \(\mu\)를 넣은 것을 \(k\)차중심 적률 \(\mu_k\)로 정의합니다. 수식을 써보면 이렇습니다.
$$\mu_k=E((X-\mu)^k))$$
그리고 이 중심적률을 표준편차의 \(k\)제곱으로 나누면 \(k\)차 표준화 적률 \(\widetilde{\mu_k}\)가 됩니다. 수식은 이렇습니다.
$$\widetilde{\mu_k}=\frac{\mu_k}{\sigma^k}$$
이 개념들로, 어떤 확률분포에 대한 정보인 평균, 분산, 왜도, 첨도를 정확하게 알아낼 수 있습니다.
1
1차 적률 = 평균 = \(\mu'=\mu=E(X)\)
2
2차 적률 = \(\mu'_2=E(X^2)\)
2차 중심적률 = 분산 = \(\mu_2=E[(X-\mu)^2]=Var(X)\)
3
3차 적률 = \(\mu'_3=E(X^3)\)
3차 중심적률 = \(\mu_3=E((X-\mu)^3)\)
3차 표준화적률 = 왜도 = \(\widetilde{\mu_3}=\frac{E[(X-\mu)^3]}{\sigma^3}=\gamma_1\)
(Fisher's moment coefficient of skewness)
왜도(Skewness)란 비대칭의 정도를 나타내는 지표입니다. 데이터가 어느 쪽으로 몰려있는지 판단하는 기준이 되죠. 정규분포나 t분포처럼 평균을 중심으로 완전히 대칭인 분포는 왜도가 0이고, 오른쪽으로 긴 꼬리를 갖는 경우 왜도가 양수가 되고 왼쪽으로 긴 꼬리를 갖는 경우 왜도가 음수가 됩니다. 출처 : https://en.wikipedia.org/wiki/Skewness#/media/File:Relationship_between_mean_and_median_under_different_skewness.png
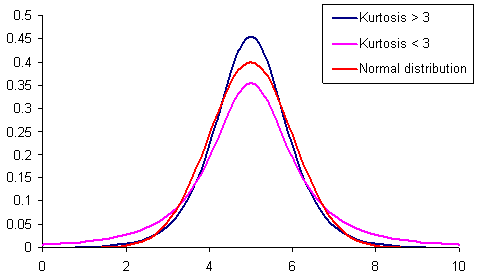
첨도(Kurtosis)란 뾰족한 정도를 나타내는 지표입니다. 데이터가 얼마나 몰려있는지 판단하는 기준이 됩니다. 첨도가 항상 3이 되는 정규분포를 기준으로, 보통 첨도가 3보다 높으면 많이 뾰족하다(leptokurtic)고 판단하고 첨도가 3보다 낮으면 꽤 완만하다(platykurtic)고 표현합니다. 출처 : https://www.vosesoftware.com/riskwiki/Kurtosis%28K%29.php
따라서 적률생성함수를 통해 구해낸 적률은 분포를 결정짓는 정보들을 뜻하겠습니다.
특히 이 적률생성함수는어떤 확률변수의 분포를 유일하고 완전하게 결정합니다(unique and completely determine). 따라서 보통 어떤 확률변수의 분포를 알고 싶다고 한다면, 그것의 적률생성함수를 구해서 이미 구해진 여러 분포들의 적률생성함수와 비교하여 분포의 종류와 평균 및 분산을 알아낼 수 있습니다.
분포별 적률생성함수
어떤 분포의 pmf 또는 pdf를 알면, 적률생성함수을 구하고 미분을 여러 번 해서 평균과 분산을 알아낼 수 있습니다. 더불어 내가 원하는 확률변수(파생변수)의 분포와 평균, 분산도 알아낼 수 있죠. 대표적으로 정규분포와 포아송분포에 대해 살펴보겠습니다. (코시분포는 적률생성함수가 정의되지 않습니다.)
1. Normal Distribution
어떤 연속확률변수 \(X\)가 \(X \sim N(\mu,\sigma^2)\)이면, \(X\)의 확률밀도함수(pdf of \(X\))는 아래와 같습니다.
이때 적분기호 뒷부분인 \( \frac{1}{\sqrt{2\pi\sigma}}e^{-\frac{1}{2}(\frac{x-(\mu+\sigma^{2}t)}{\sigma})^2}\) 부분은 평균이 \(\mu+\sigma^{2}t\)이고 분산이 \(\sigma^2\)인 정규분포의 pdf가 되므로, 이것을 전적분하면 1이 됩니다. 따라서 우변에는 적분기호 앞부분만 남네요.
통계학에서 통계적 추론이란 모집단의 특성을 알아내기 위해 점추정량을 구하거나 신뢰구간을 구하는 '추정'과, 귀무가설과 대립가설을 세우는 '검정'을 하는 것을 뜻합니다. 이때 점추정량을 만들어내기 위해 여러 가지 시도를 할 수 있겠죠. 이때 이 점추정량 역시 새로운 확률변수입니다. 예컨대 우리가 흔히 보는 표본평균 \(\overline{X}=\frac{1}{n}\sum_{i=1}^{n}X_i\)도 새로운 확률변수입니다. \(\max(X_1,X_2,X_3)\) 같은 형태도 새로운 확률변수이고, 위의 예제와 같이 서로 사칙연산을 해서 확률변수를 새롭게 만들 수도 있을 것입니다. 이때 적률생성함수는 이렇게 만들어진 확률변수들의 분포가 어떤 분포인지 결정해주므로 매우 유용합니다.